Embodied VLM
Perception for agents and robotics
Building multimodal systems that can perceive, reason, and act in 3D environments for navigation and embodied decision making.

I am a Principal Research Scientist and Tech Lead at NVIDIA Research, where I work with the LPR team led by Jan Kautz. My current research focuses on embodied foundational models, efficient transformer architectures, and spatial reasoning. I am deeply involved in VLM and VLA foundation model efforts across Cosmos and Isaac GR00T.
Before joining NVIDIA, I earned my Ph.D. at the VLLAB at UC Merced, advised by Ming-Hsuan Yang. I have been fortunate to receive the Baidu Graduate Fellowship, the NVIDIA Pioneering Research Award, and the Rising Star EECS recognition.
Current Focus
Research Themes
I work on making multimodal systems more grounded, more efficient, and more capable in open-world environments.
Embodied VLM
Building multimodal systems that can perceive, reason, and act in 3D environments for navigation and embodied decision making.
Efficient Models
Designing token-efficient architectures and attention mechanisms that preserve detail without paying the full compute cost.
Spatial Intelligence
Connecting images, language, and geometry so models can reason about structure, localization, and relationships across views.
Cosmos 3 is NVIDIA's omnimodal world foundation model that unifies understanding, generation, simulation, and action across text, image, video, audio, and robot actions for Physical AI. I serve as a core contributor on its spatial and embodied capabilities.
LoHo-Manip is a modular framework that scales short-horizon vision-language-action policies to long-horizon manipulation, using a task-management VLM that predicts subtask sequences and 2D visual traces to guide the executor with implicit progress tracking, replanning, and recovery.

GR3D is a spatial vision-language model that unifies explicit 2D, implicit 2D, and monocular 3D grounding in a single framework, decomposing spatial understanding into grounded 2D perception followed by 3D inference.
OmniVinci is an omni-modal LLM with new architecture (OmniAlignNet, Temporal Embedding Grouping, and Constrained Rotary Time Embedding) and a 24M-conversation data pipeline, achieving state-of-the-art joint understanding of images, video, audio, and text with far fewer training tokens.

Compact GSPN (C-GSPN) is a ViT block with compressed spatial propagation and fused CUDA kernels that cuts propagation latency by nearly 10x, using a two-stage distillation scheme to scale subquadratic spatial propagation networks to vision foundation models.
SR-3D unifies single-view 2D and multi-view 3D representations for flexible region prompting and grounded spatial reasoning.
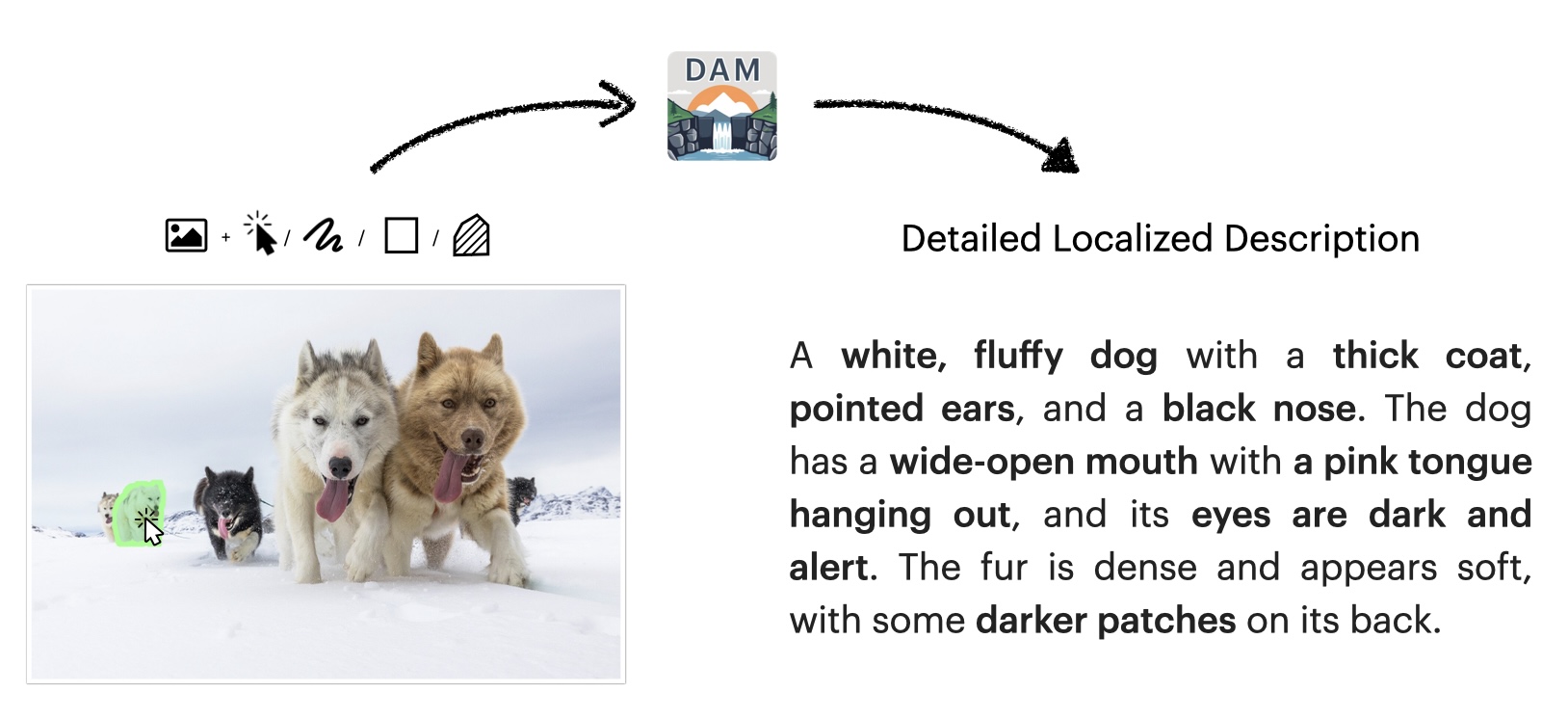
DAM generates detailed localized captions for user-specified regions in images and videos, preserving both local detail and global context.
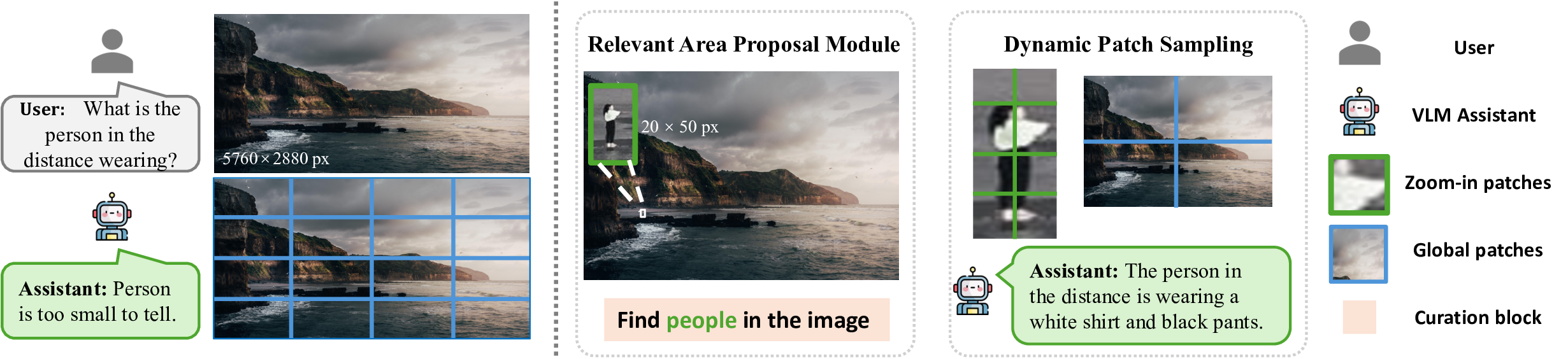
TEVA improves high-resolution image understanding by dynamically selecting detail-rich regions while keeping token usage efficient.
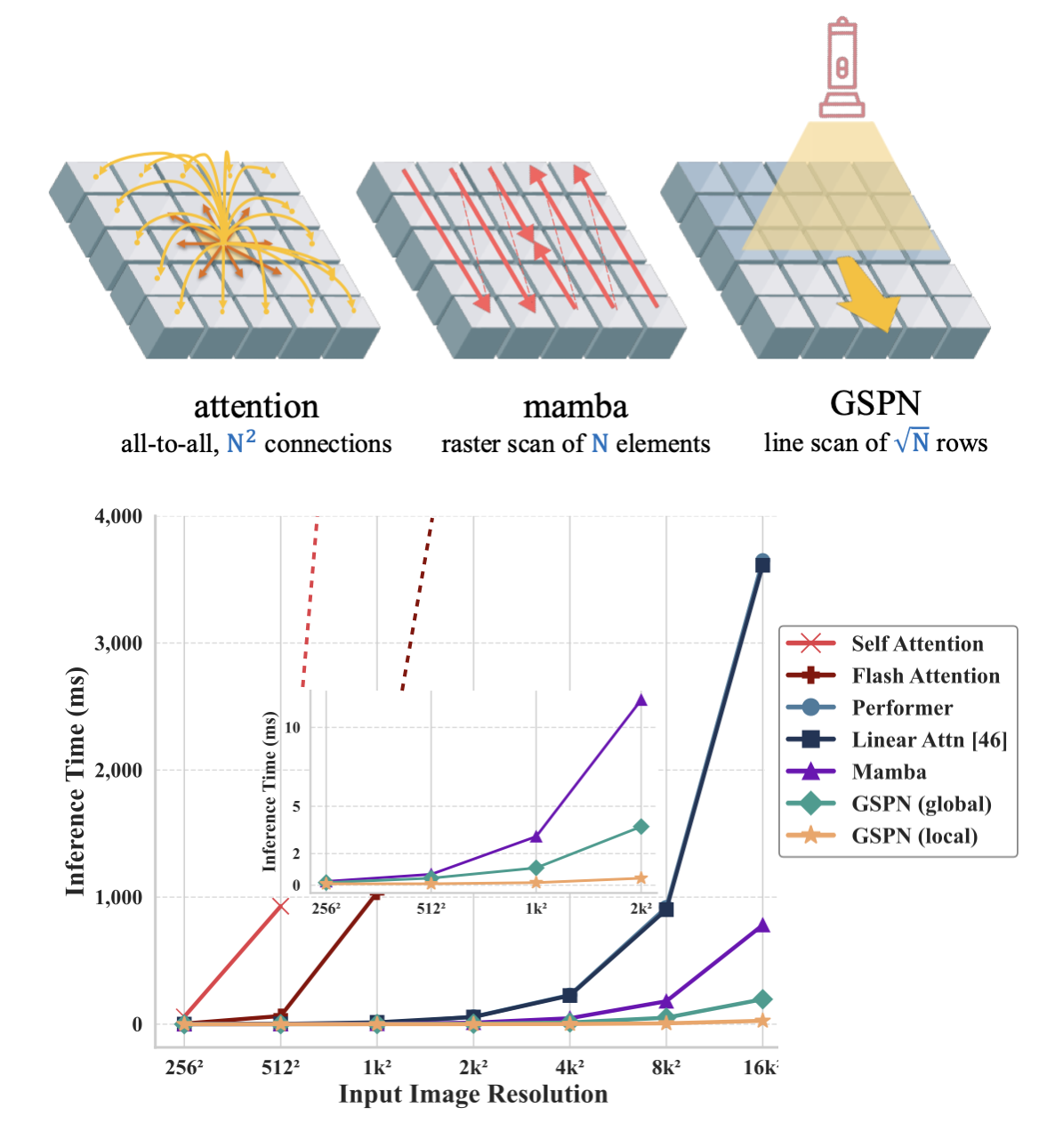
GSPN is a fast vision attention module that accelerates generic vision foundation models for high-resolution input images.

NaVILA is a two-level framework that combines VLAs with locomotion skills for navigation. It generates high-level language-based commands, while a real-time locomotion policy ensures obstacle avoidance.
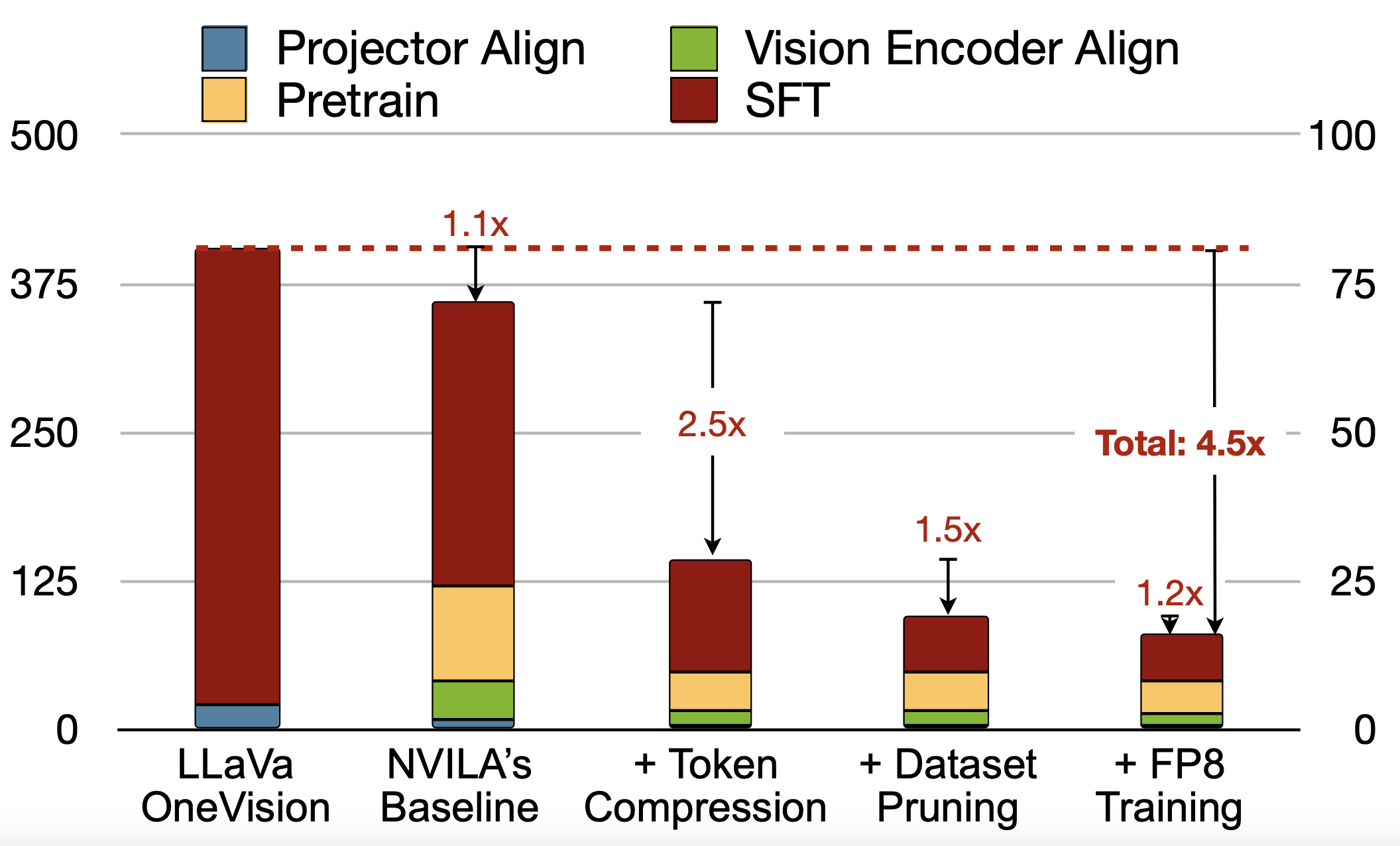
Efficient frontier VLM models with efficient training and inference.
No Pose, No Problem: Surprisingly Simple 3D Gaussian Splats from Sparse Unposed Images
SpatialRGPT is a grounded spatial reasoning model that can reason about spatial relationships in images.
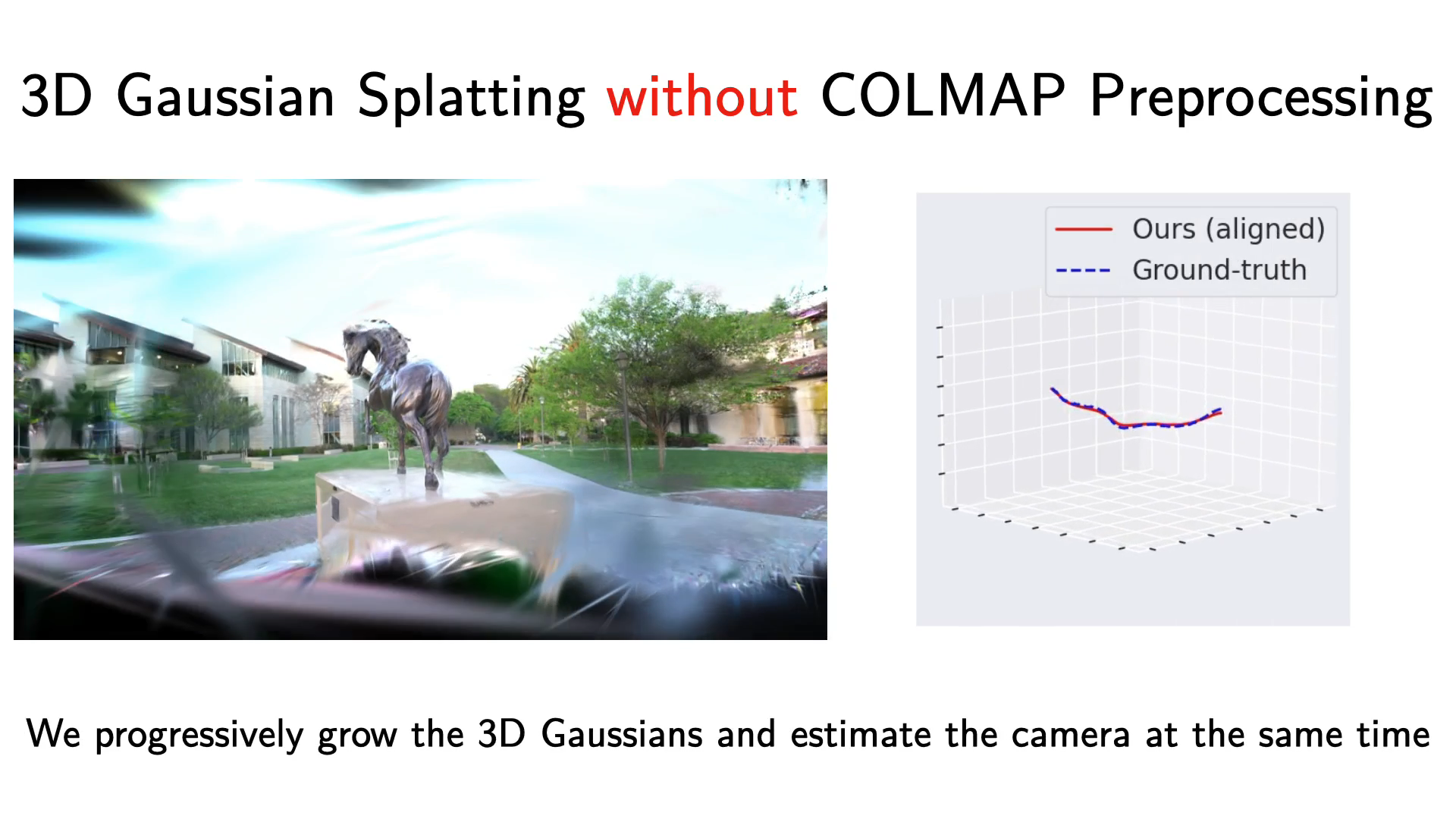
3D Gaussian Splatting without COLMAP computation.

We present ODISE: Open-vocabulary DIffusion-based panoptic SEgmentation, which unifies pre-trained text-image diffusion and discriminative models to perform open-vocabulary panoptic segmentation.